这是笔者公开发表的关于漏洞挖掘的第二篇文章,与发第一篇的时间差不多间隔了整整一年,在这一年里虽然工作细碎,但我还是抽出了大量的时间关注安全,因为当初的既定目标就是走安全的路。这一年了也做了不少关于安全方面的事情,比如参加各大*SRC的漏洞提交什么的,曾今有一段时间也是走火入魔了一样,但是后来我停下来了,因为我觉得那种事情偏离我最初对“漏洞“挖掘的定义,看了那些提交的所谓“漏洞”,基本都是功能缺陷的漏洞(这里只说PC终端产品,Web漏洞不在本文讨论范围内),比如说过xxx主防加载驱动,写启动项,干掉xxx杀软等等,这些也属于一个产品的漏洞,但是这种功能缺陷型漏洞大都带有一种高层次对抗的意味,这种漏洞的挖掘和利用过程完全脱离了对底层二进制级别的指令执行过程的分析,这样的漏洞挖掘中的唯一用处就是你可能对一个操作系统上的各个小子系统更加熟悉,当然前提是你是一个喜欢总结追根摸底的人,你会“系统性“学习,否则的你只能成为一个什么武功都会个一招半式的人,只能知其然,却不能知其所以然。漏洞挖掘还是要回归本质,就我所知,目前国内真正做漏洞挖掘比较务实并且有很多成果的公司瀚海源和360。瀚海源和安全宝从发展过程来看比较类似,但是前者偏向Host安全,后者偏向Web安全。看过瀚海源的一些博客以及给微软提交的漏洞,觉得他们做的才是真正的漏洞挖掘。
言归正传,回到本文的话题,前一篇文章是关于漏洞挖掘的Fuzz方法并且介绍了Windows XP里面的AFD.sys里面的Local DOS漏洞,这篇文章是关于漏洞挖掘的另一种方法—静态扫描潜在危险函数。为了使文章内容充实有干活,笔者在自己使用静态扫描发现的漏洞中选择一个经典栈溢出来讲解,包括对该溢出的挖掘过程,利用方法,shell code构造等。
Part Ⅰ静态扫描方法论及工具开发
漏洞挖掘的方法众多,比如Fuzz,源码审计,二进制代码扫描等等。Fuzz属于动态方法,凡是动态方法的都需要有一个比较全面的路径覆盖,所以需要比较高的自动化系统,实现成本比较高。源码审计实现比较简单,但是需要接触到源代码,所以对很于第三方检测机构来说一般得不到源码无法采用这种方法。
接下来就是今天的主角了—二进制代码扫描:这种漏洞挖掘方法的思路就是扫描目标程序的二进制文件,通过PE文件分析,指令分析等来发现目标程序中存在的潜在漏洞代码。最容易想到的就是通过扫描PE文件的倒入表,查找是否存在危险函数,这种扫描方法速度快,而且比较有效,但是也有缺点:检出率不高,存在遗漏,因为只能扫描到倒入表这一方面,而如果一些模块是使用了静态lib链接的话,那就可能直接把某些危险函数嵌入了模块内部,倒入表中不存在。所以还需要加以指令分析的方法,但是指令分析的实现难度和成本都比较高,因为要考虑到所有的漏洞模式,这也导致了另一个缺点检测速度非常慢。
对于零散的漏洞挖掘人员来说,没有经历和时间来实现比较系统化的工具,但是倒入表的扫描这一点来说还是比较容易实现的。如果不闲麻烦,找到一个程序目录,然后使用Dependency Walker一个一个去查找倒入表,找到你认为危险的函数,谁会有这么多体力呢……所以,动动小手写个工具吧,BinCodeAudit就此诞生了。
BinCodeAudit是一个基于Python语言开发的用于批量扫描程序导入的潜在危险函数的工具,该工具的最初设计结构如下图:

P1
现在,除了UI界面之外其他功能都已经实现。这里贴出一下目前的一个命令行模式的主程序模块代码:
代码:
#!/usr/bin/env python
#coding:utf-8
"""
Author: tishion--<tishion@163.com>
Purpose:
Created: 2014/2/9
"""
import os
import sys
import string
from symscan import ImportSymScanner
from reportmaker import ReportMaker
g_str_help = """
Usage: python bca <target-dir>
target-dir : target directory path to be scanned.
e.g:
python bca "c:\window\system32"
"""
def main():
global g_str_help
#process command line arguments
if len(sys.argv) <= 1:
print 'Sytanx Error: missing argument.'
print g_str_help
return
target_dir = sys.argv[1]
if not os.path.isdir(target_dir):
print 'Error: the target-dir:[' + target_dir + '] is not a directory!'
return
#创建一个扫描器
sc = ImportSymScanner()
#添加需要扫描的目标函数
sc.add_sym('msvcr90.dll', ('wcscpy', 'strcpy', 'swprintf'))
sc.add_sym('msvcr80.dll', ('wcscpy', 'strcpy', 'swprintf'))
sc.add_sym('msvcrt.dll', ('wcscpy', 'strcpy', 'swprintf'))
sc.add_sym('kernel32.dll', ('lstrcpyA', 'lstrcpyW', 'lstrcatA', 'lstrcatW'))
#开始扫描
print 'Scanning ...'
rl = sc.do_check(target_dir)
print 'Scanning is Done!'
#生成报告
rm = ReportMaker()
print 'Generating report ...'
rm.GenerateNewReport(target_dir, rl)
#打开报告文件
print 'Opening report ...'
rm.OpenReport()
if __name__ == '__main__':
main()
使用方法:
代码:
F:\Projects\Python\BinCodeAudit>bca.py "F:\Program Files (x86)\SysinternalsSuite"
Scanning ...
Scanning is Done!
Generating report ...
Opening report ...
生成的报告使用HTML文件的方式:

P2
这个项目已经在sf创建了版本,如果有兴趣的同学可以申请一起加入开发维护,如果有好的比较大功能想帮忙添加也欢迎找我拉取分支。
Git 地址:http://git.code.sf.net/p/bincodeaudit/code
SourceForge项目主页:http://sourceforge.net/projects/bincodeaudit
Part Ⅱ静态扫描实战及经典栈溢出一例
上面简单介绍了静态扫描工具的开发,开发工具不是目的,使用工具去找到更多的漏洞才是我们的目的,磨完刀就可以试一下了,我在这里选取Notepad++这个程序来做实例。
一、扫描二进制代码,发现目标
首先用我们的工具来扫描整个安装目录下的所有文件,以检测是否有目标函数,这里我们的目标函数选取了CRT库函数strcpy,wcscpy,以及Kernle32模块中的lstrcpyA/W,lstrcatA/W。然后直接启动扫得到扫描结果报告:
 P3
P3
可以看到能够导致栈溢出的危险函数还是很多的,主程序里面只检测出来两个危险函数,而其他的大都是notepad++的插件模块,看来Notepad++插件的开发者贡献的代码质量并不是很高。现在选定一个目标,我们就以notepad++.exe这个程序中导入的lstrcpyW这个函数为靶子,然后就要开始分析了。
二、尝试静态分析函数调用点,发现漏洞触发场景
首先静态分析notepad++.exe看是否可以找到调用lstrcpyW函数的地方使用了我们可以控制的数据作为源字符串参数的。但是……经过使用IDA初步查看,该函数的调用点太多,静态分析的方法需要耗费太大的人力:

P4
所以,这一步就直接略过了,因为这只是找到问题的一种方法,既然此方法成本太高,就没必要纠结一定要用这种方法,以后有机会再选择一个可以直接通过静态分析直接找到漏洞的例子。
三、调试分析,发现漏洞触发场景
静态分析方法行不通,那就直接调试了,调试的时候要明白三点:
1.我们要找的是栈溢出
2.溢出函数可能发生在lstrcpyW
3.我们要找到在调用lstrcpyW函数的时候源字符串使我们可控的
清楚上面三点我们就要想方法通过调试器来协助我们找到上面3所描述的情景了,很容易想到要在lstrcpyW函数下断点,并且每次断点的时候都要把lstrcpyW函数的源字符串输出,以便于我们确认该数据是否可控。
打开Noetpad++.exe然后用Windbg附加进程,设置断点:
代码:
bp kernel32!lstrcpyW "du poi(@esp+8);g"
然后要做的就是操作Notepad++,并且观察调试器的输出了,这也是一个比较耗时的过程,需要有耐心,把Notepad++的各种按钮点一遍,肯定可以找到我们需要找的,寻找的过程在这里不详细说了,我直接说出一个场景,就是在使用Notepad++的插件CCompletion这个插件的Goto identifier的时候,如下图所示。在未选中任何字符串时,使用菜单插件-CCompletion-Goto identifier这个功能,就会发现当前编辑区域的所有字符串都被选中并且被lstrcpyW这个函数处理了四次。
![YZ4HSI9@4SW8Z`$Y]PFXK66.png](data/attachment/forum/201501/15/130421meq0202tttt5iipo.png "YZ4HSI9@4SW8Z`$Y]PFXK66.png")
P5
找到这个场景之后我们就可以进一步确认,lstrcpyW这个函数是否存在栈溢出的可能,输入很长的数据,然后看一下程序是否会出问题Crash。
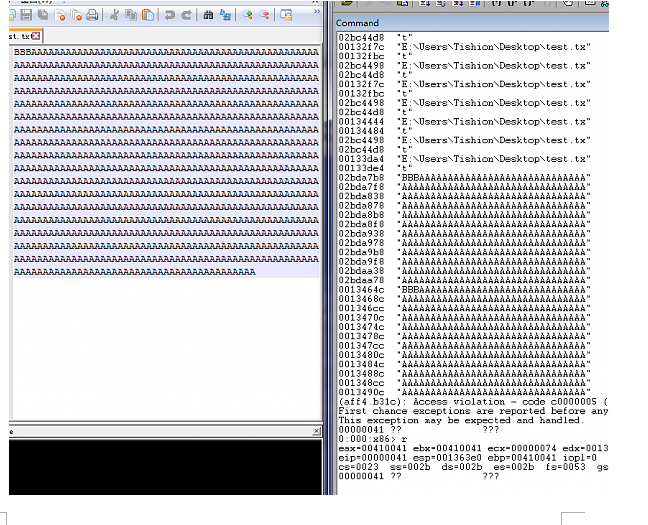
P6
可以看到,在第二次拷贝之后,程序Crash了,因为发生了AV异常,现在已经基本可以断定这里存在溢出的可能了,但是还需要跟加深入的对这两次的调用进行分析。下面要更换一下条件断点的判断条件了,只有当拷贝的源字符串是我们输入的字符串的时候才断下:
代码:
bp kernel32!lstrcpyW ".if(poi(poi(@esp+8))=0x00420042) {kv1;} .else{du poi(@esp+8);g;}"
因为我们选择的测试字符串是BBAAAAAA……所以只要判断源字符串的前4个字节是否为0x00420042就行了。然后重复我们刚才的Crash场景。既然Crash是发生在第二次拷贝之后,所以我们需要看一下第二次拷贝之后栈的情况:
![2[BR1$(LB_6GT5Y85`~]ACP.png](data/attachment/forum/201501/15/130526j44qmugkhwmz8msg.png "2[BR1$(LB_6GT5Y85`~]ACP.png")
P7
从以上情况可以看出,栈已经被我们的数据覆盖了,这里要有一点预先判断,如果栈溢出,那么在接下来的程序运行过程中一定会因为某一个ret指令导致栈中的数据进入eip寄存器,并且这个值应该是0x00410041,然后程序从0x00410041开始继续执行,考虑到这一点我们就可以在0x00410x0041下一个断点,然后继续执行程序。
U[_LMT275JQ3%}HR.png")
P8
程序最终在0x00410041触发了断点,到这里,已经非常明确了,程序发生了栈溢出,并且我们成功劫持了EIP,下面我们要计算这个eip取到的0x00410041位于我们的数据中的偏移地址,也就是上层函数的返回地址在栈中存放的位置,还记得第二次拷贝字符串的时候的目标地址么?没错是0x00135c7c,此时esp的值为0x1360b0,所以我们计算差值:
代码:
0:000:x86> ?0x1360b0-0x00135c7c
Evaluate expression: 1076 = 0x00000434
由此得出在我们构造的数据的0x00000434-4个字节处的一个DWORD值就是我们可控EIP的值,下面我们验证这一结论,保存我们刚才构造的那个文件,然后用WinHex打开,编辑偏移0x00000434字节处的一个DWOR值这里注意大小端的问题 :

P9
然后保存这个文件,然后再用这个文件来触发刚才的场景,看一下EIP是否如我们预料的为0x004142430:
P10
可以看到,EIP已经是我们期望的0x00414243了,好吧,到这里这个溢出点已经被我们完全掌握了,到此为止这已经是一个完美的可利用溢出了,下面就是要写ShellCode来达到利用溢出的目的了。
这个ShellCode的构造也不是十分顺利,篇幅比较长,所以本文先写到这里,下次会把ShellCode的构造过程详细整理一下再分享出来。
|

 发表于 2015-1-15 13:10:40
发表于 2015-1-15 13:10:40
 是本人不?我去,好神奇,感谢逗比的分享!~~
是本人不?我去,好神奇,感谢逗比的分享!~~

